Inference: The Process of Constructing New Answers from Learned Patterns
AI has two stages: training and inference. Training is the process of adjusting internal weights by processing large amounts of data. Inference is the process by which a fully trained model generates answers for new inputs.
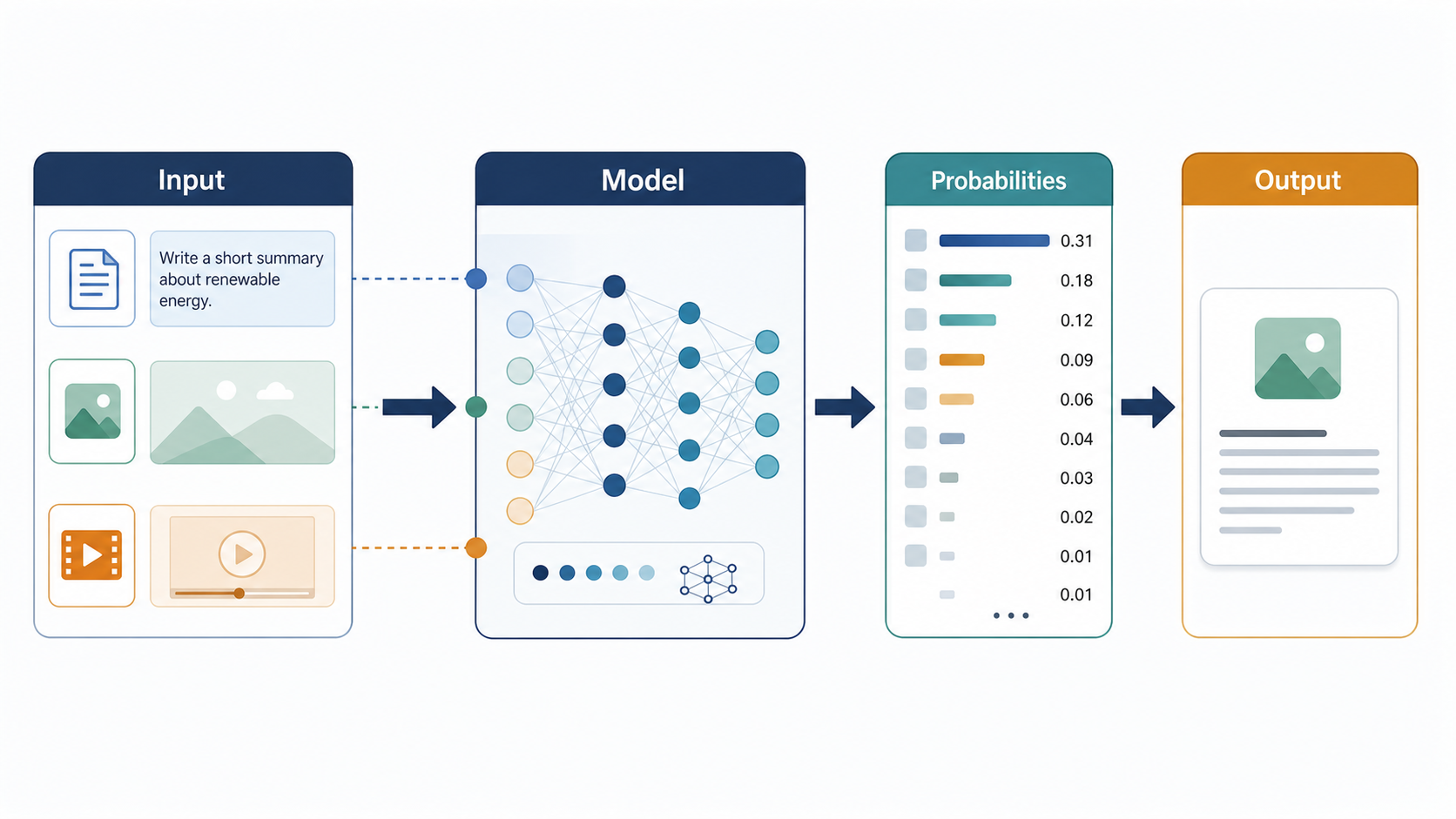
Every calculation that takes place from the moment you send AI a question is inference. The model no longer modifies itself. Instead, it uses the weight matrices formed during past training to calculate the most plausible output.
How Does Inference Proceed?
To the user, it looks like "input → output," but internally a very fast calculation repeats itself. The basic structure is similar for text, images, and video: calculate the "next state" based on the current state, then feed the result back into the input and continue.
The inference process can be broken down into four broad steps:
- The input is converted into numerical form. Text is split into tokens; image or video prompts are also ultimately represented as number arrays.
- The model views the entire input at once and calculates the context: what conditions are important and what relationships exist.
- It calculates the probability of each possible candidate for what comes next. For text, the candidates are the next tokens; for images, the next stage of pixel states; for video, the next frame state.
- One candidate is selected and incorporated into the output, then that result is fed back into the input and the same process repeats.
This process is implemented differently depending on the medium: for text, it appends tokens one by one; for images, it progressively refines a number array; for video, it builds temporally connected frames.
How Does Inference Work for Text?
A generative AI model does not complete a response sentence all at once. Internally, it constructs the sentence by predicting and appending tokens one at a time.
For example, suppose the following question is entered:
Explain why tokens are important.
The model first splits this sentence into tokens and converts each token into a numerical vector. It then calculates the entire input at once to form a context. In this process, the model probabilistically constructs a typical explanatory structure: definition, reason, example, summary. This is not the result of consciously applying specific rules; it reflects explanatory patterns that appeared frequently in the training data.
In the next step, the model calculates the probabilities of candidate tokens that could follow. It selects the token that is most natural given the current context and adds it to the output. The selected token is then fed back into the input, and the same process repeats. This repetition continues until the sentence is complete.
Because of this structure, even the same question may not always produce an identical response. At each step, multiple candidates exist, and the expression can vary depending on how the selection is made. In creative writing, this variability is an advantage; for tasks requiring precision, the selection range is narrowed to increase stability.
What Happens in Image Generation?
Image generation works differently from text. Text appends tokens one at a time, but images are progressively refined across multiple stages. Most image generation models start from near-random noise and gradually remove that noise to form shapes.
The process is as follows:
- A nearly random noise image is created.
- The prompt conditions are incorporated to calculate a "slightly more plausible state."
- This process is repeated dozens of times, progressively concretizing: outline → shape → detail.
- In the final stage, color, texture, and edges are refined.
An image is a massive numerical matrix made up of millions of pixel values. A 1,024×1,024 image alone has over one million pixels, and that number grows when color is factored in. The model does not complete this enormous number array all at once. It refines it incrementally over multiple passes. Progressively shifting the overall numerical structure is more computationally stable.
Understanding this structure also explains why fingers look strange or text appears garbled when AI generates images of people. The model does not draw a hand by understanding anatomy. It adjusts a number array based on visual patterns that appeared frequently in the training data. For small regions like hands that contain complex structure, the fine detail can break down during the process of balancing the overall image. Text similarly suffers from small distortions because it is generated as a visual pattern rather than being written according to spelling rules.
Why Is Video Generation Harder?
Video is a sequence of images connected along a time axis. It is not enough for a single frame to look natural; adjacent frames must connect consistently with each other.
Video inference proceeds with the following structure:
- Basic conditions for the scene are set. Example: "A person is walking outdoors."
- The first frame is generated.
- When generating the next frame, the visual information from the previous frame is included as input for the calculation.
- This process repeats to construct a temporally connected scene.
The key is temporal consistency. The character's position, facial features, and background structure must be preserved from frame to frame for the result to look natural. The model does not create each frame completely independently. It uses the previous state as a condition and calculates the next.
The flickering or shape collapse that appears in videos occurs when this consistency is not sufficiently maintained. For example, if a face is positioned correctly in one frame but the eyes shift slightly, the clothing pattern changes, or a background object disappears in the next frame, a viewer immediately notices the unnaturalness.
Text can recover through meaning even when one sentence differs slightly. But video involves visual information connected continuously, so even small changes stand out prominently. This is why video generation places a greater computational burden than text or images and is structurally more difficult.
Key Takeaway
Inference is the process of using learned weight matrices to calculate the next state for a new input. The model does not modify itself; it calculates probabilities based on the already-learned numerical structure. Text is extended token by token; images are progressively refined as number arrays; video connects frames while maintaining temporal consistency. Every moment we use AI, what is actually happening is a very rapid computation of an enormous matrix refined through training.