What Does It Mean to Adjust Weights in AI Training?
When we say AI learns, we essentially mean "it adjusts its weights." So what are weights, and why does changing them constitute learning? An AI model is fundamentally a function that takes an input and calculates an output. In its simplest form, it looks like this:
Here, is the input, is the weight, is the bias, and is the output. The meaning is simple: multiply the input by some factor () and add a base value () to produce the result.
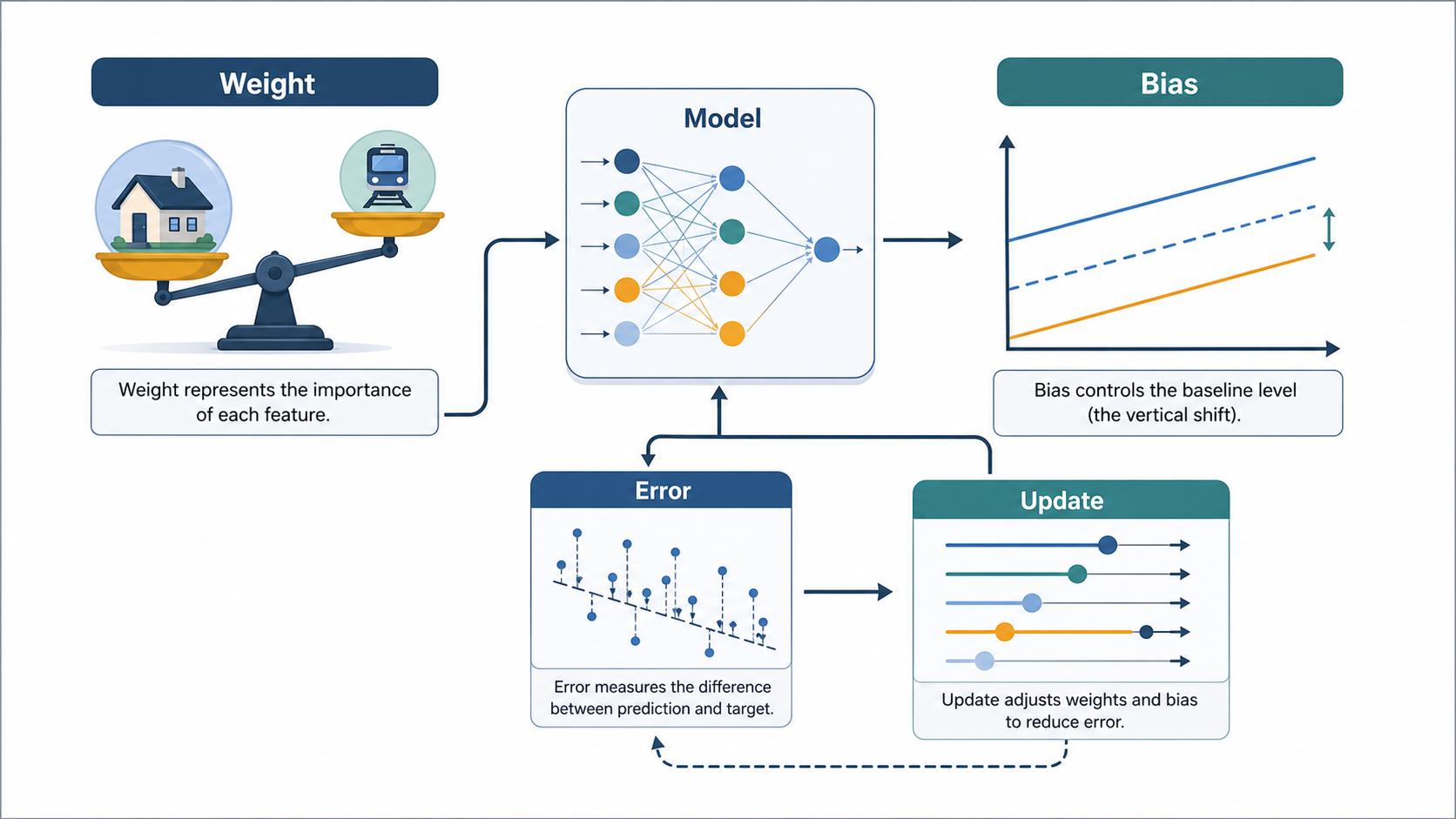
A weight is a number that represents how much an input influences the result. For example, suppose we are predicting the price of a house. If the inputs are "floor area" and "distance to the subway station," floor area typically has a greater influence. In this case, a larger weight is assigned to floor area and a smaller weight to distance from the subway. In other words, weights are numerical representations of how important each input factor is.
A bias is a value that sets the model's baseline starting point. It ensures the output is not zero even when all inputs are zero. From a graphical perspective, weights determine the slope, while bias shifts the graph up or down. Without bias, an AI model would be overly simplistic and unable to adequately represent real-world data.
How Are Weights and Biases Stored and Calculated?
A real AI model does not perform this calculation just once. Thousands or millions of weights exist simultaneously, and these values are stored as matrices. A matrix is a table that organizes numbers in rows and columns. For example:
This table is a simple collection of numbers, but each number represents a single connection strength. Inputs are also represented as vectors (numbers arranged in a row or column):
The model's calculation proceeds as follows:
This expression means: "multiply a set of input numbers by a weight table and add the bias." Matrix multiplication is a computation method that combines multiple inputs simultaneously to produce new numbers. When this calculation is repeated across multiple layers, simple number combinations gradually come to represent complex patterns.
How Are Numbers Adjusted to Reduce Error?
So what does learning actually change? AI starts with randomly initialized weights, so initial predictions are almost never correct. After making a prediction, it calculates the difference between the predicted value and the correct answer. This is called the loss or error.
A large error means the current weight configuration is poor. So the weights are adjusted slightly in the direction that reduces the error. Expressed as a formula:
Don't be alarmed by the formula! You only need to understand its general meaning.
Each element of the formula means the following:
- : the error expressed as a numerical value (the loss function)
- : the value that tells us in which direction and by how much to change the weight
- : the value that determines how large a step to take at each update (the learning rate)
The essence is simple: move the number slightly in the direction that reduces error. When this process is repeated tens of thousands of times, the weights become progressively more refined. A numerical structure forms that accurately reflects the relationship between inputs and outputs. Note that AI does not store sentences or hold knowledge in textual form. The result of training is a massive collection of numbers. What we call a "model file" is in reality a file of matrix data containing countless weight values. Text generation models, image generation models, and video generation models all have enormous weight matrices at their core.
In summary, adjusting weights means changing the importance attributed to each input, and adjusting biases means changing the model's baseline reference point. AI training is the process of repeatedly modifying these numbers to reduce error. AI's intelligence depends on how precisely the numbers within its many matrices have been tuned.
These tuned matrix values determine what output the AI produces when it receives a new input. These values are stored in a file and loaded whenever they are needed. Every moment we use AI is ultimately a process of very rapidly computing an enormous weight matrix that was refined through training.