The Transformer Model That Popularized Generative AI
AI has changed dramatically in recent years. Where the AI of the past could translate short sentences or answer simple questions, today's AI writes lengthy reports, holds contextually aware conversations, and generates images and audio. At the center of this rapid transformation is a model architecture called the Transformer.
The Transformer was first proposed in a 2017 paper by Google researchers titled Attention Is All You Need. This paper introduced a new structure that stepped away from sequential processing and instead examined an entire sentence all at once.
Original paper: https://papers.neurips.cc/paper/7181-attention-is-all-you-need.pdf
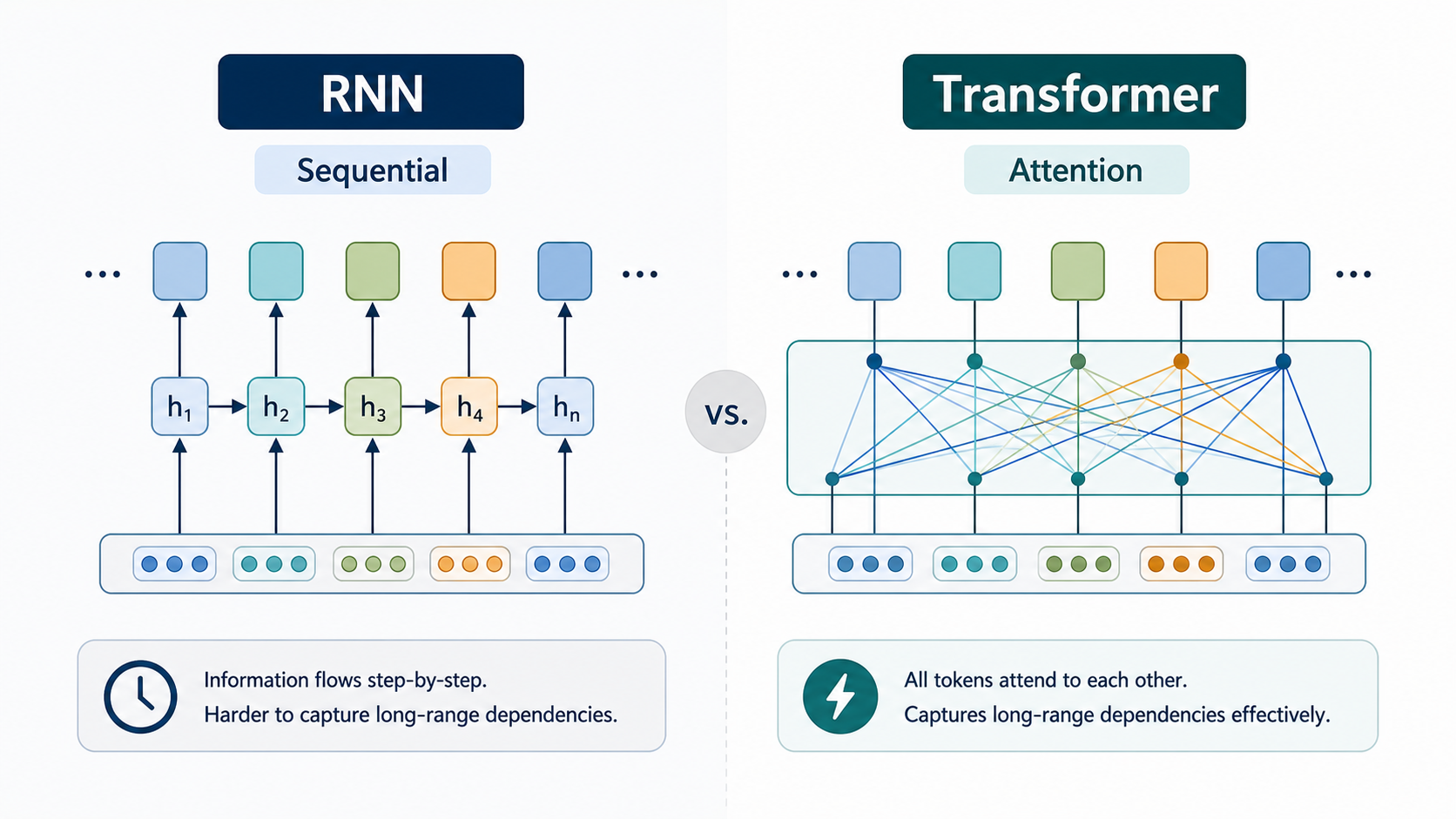
AI models for processing language had existed before. Notable examples include RNNs (Recurrent Neural Networks, which read sentences from beginning to end in order) and LSTMs (Long Short-Term Memory models, designed to retain information over longer sequences). However, these approaches required processing one word at a time in order, making them prone to forgetting earlier information in long sentences and slow to train. In particular, as sentences grew longer, computational demands increased significantly.
The Arrival of the Attention Mechanism: Focusing on What Matters
To address these limitations, the Transformer used a concept called attention as its core mechanism. Attention is literally "a way of focusing more on the parts that matter." For example, in the sentence "I went to school today," the word "today" is closely related to "went." The Transformer compares all words in a sentence simultaneously and numerically calculates how much each word is related to every other word. This is called self-attention, a mechanism that calculates the relationships between words within a sentence.
The greatest advantage of this approach is the ability to view the entire sentence at once. Instead of processing words in order, all words reference each other simultaneously, allowing even long contexts to be understood stably. In addition, calculations can be performed in parallel, enabling very fast training on parallel computing hardware such as GPUs (Graphics Processing Units). This characteristic made it possible to greatly expand model size, and large-scale models with billions or more parameters emerged as a result.
The Transformer architecture drove revolutionary performance improvements in language processing. Subsequently, various models were developed on the Transformer foundation, including BERT (a model with strengths in understanding context) and GPT (a model specialized in generating text). The name GPT itself stands for Generative Pre-trained Transformer, indicating that it is a Transformer-based generative model. Most large-scale language models in use today are built on this architecture.
The Transformer's Expansion and Its Role in Generative AI
The Transformer has expanded beyond text into the image and audio domains. In the image domain, the Vision Transformer (ViT) emerged, dividing images into small patch units for processing. In the audio domain, speech signals are divided into fixed units and their relationships are calculated. More recently, multimodal models that process text, images, and audio simultaneously are also designed around the Transformer architecture.
In generative AI, the Transformer plays a particularly important role. Generative AI creates outputs by repeatedly predicting the next element. In text generation, it predicts the next word; in image generation, it predicts the next pixel or denoising step. The ability to accurately understand context throughout this process is essential, and the Transformer's attention mechanism makes this possible. This is why it can maintain the context of long sentences and generate natural, coherent results.
In summary, the Transformer was more than a new algorithm. It was a structural turning point that unlocked the scalability of artificial intelligence. The ability to view an entire sentence at once, focus on important relationships, and enable large-scale parallel training is what made today's generative AI possible. Behind the popularization of generative AI stands the Transformer model.