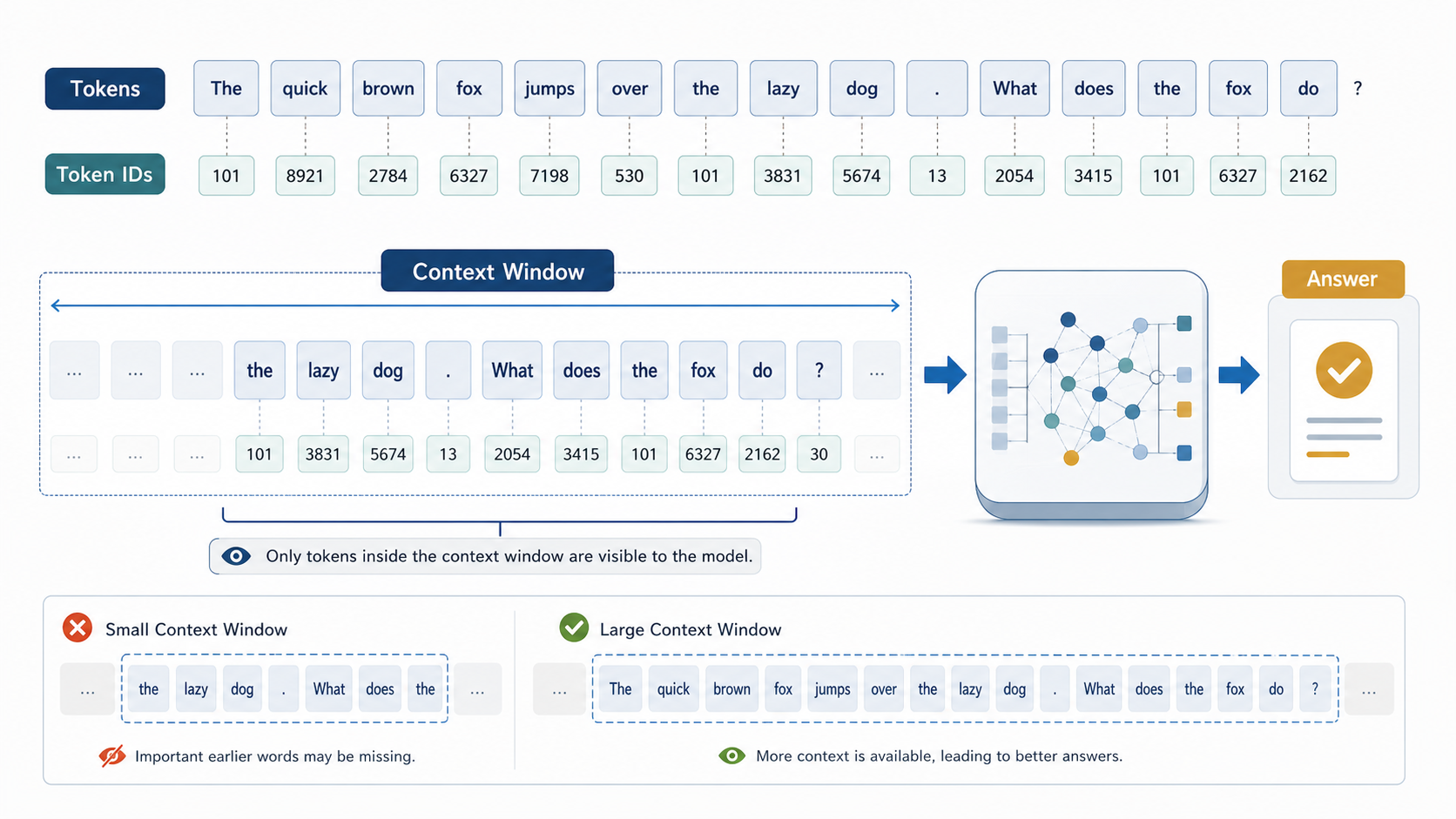
Tokens and the Context Window
Generative AI looks like it reads text, but it actually calculates numbers. The sentence you enter is first broken into fixed units, those pieces are converted to numbers, and then the model probabilistically predicts what comes next. The unit of calculation used here is the token, and the maximum range the model can refer to at one time is the context window.
What Is a Token?
A token is the basic computational unit a model uses to process text. To a person, tokens look like words, but in practice they can be broken down further.
Take the following sentence as an example:
The weather is really nice today.
A person might read this as six words, but inside the model it may be split like this:
[The] [weather] [is] [really] [nice] [today] [.]
Each of these pieces is a token. Each token is then converted to a number, and the model calculates the relationships among those numbers to predict the next token. Generating a sentence is not a matter of retrieving whole words. It is a calculation process of appending tokens one by one.
Why Is the Word Count Different from the Token Count?
The number of tokens does not exactly match the number of words. Even sentences of the same length can have different token counts.
Take this English word as an example:
unbelievable
Inside the model, it may be split like this:
[un] [believ] [able]
The same applies across languages. Many languages attach grammatical endings or particles to a word stem, and the model splits each of these into its own token, so the token count climbs.
This is why the length a person perceives and the computational cost the model experiences may differ. The model judges the amount of computation based on token count, not character count.
As a rough guide, 1,000 English words is approximately 1,200–1,500 tokens. Languages with rich word endings or non-Latin scripts often produce more tokens for the same amount of meaning.
What Is the Context Window?
The context window is the maximum number of tokens the model can refer to at one time. The question, the prior conversation, system instructions, and the model's responses are all included within this range.
For example, suppose you are using a model with a context of 8,000 tokens. If the conversation already entered amounts to 7,500 tokens, the model can only generate its response within the remaining 500 tokens. Once this range is exceeded, the oldest content is truncated or ignored.
Because of this, in long conversations you may observe:
- Conditions set earlier in the conversation disappear
- Agreed-upon formatting breaks down
- Content already explained earlier is asked about again
This is not a failure of comprehension. It is because the accessible range has been exceeded.
What Happens When You Handle Long Documents?
When you enter a long document such as a report or academic paper all at once, the full content may not fit within the context. In this case, the model generates a summary based only on what it can access. This can result in summaries that focus on the beginning of the document or omit specific details.
Models with a larger context can process more content simultaneously, but this is never unlimited. There is always a limit to the calculation range.
How Are Tokens and Cost Related?
Many AI services calculate costs based on the number of input and output tokens. The longer the question and the longer the response, the higher the cost. Repeated sentences or unnecessary background explanations directly translate into additional computation.
Structuring your input is important for efficiency.
For example, this type of request uses many tokens:
I'm currently trying to write a report.
The topic is about AI ethics,
the length should be about 5 pages,
I'd like it not to be too stiff,
and please include the risks, benefits, and future outlook.
The same content can be expressed more concisely:
Topic: AI ethics
Length: 5 pages
Include: risks, benefits, future outlook
Tone: academic but not overly stiff
The same applies when working with long documents. Rather than entering 60 pages all at once, it is more reliable to divide them into sections, summarize each part separately, and then consolidate at the end.
Summary of pages 1–10
Summary of pages 11–20
Combine the above summaries into a single 3-page summary
Processing in stages like this lets you reflect the full content without exceeding the context window.